BackPropagation
这部分讲如何高效地计算神经网络中的梯度。
链式法则
多元复合函数的求导公式利用了偏导数的链式法则chain rule,注意下面偏导数的表示形式。
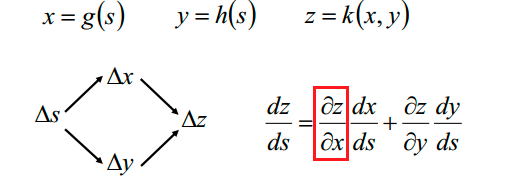
BackPropagation
看一下我们要计算的梯度形式,每一个训练样本的损失函数为$l^n$,最终的损失函数$L(\theta )$ 是所有训练样本的summation。目标是求对不同$w$的梯度:
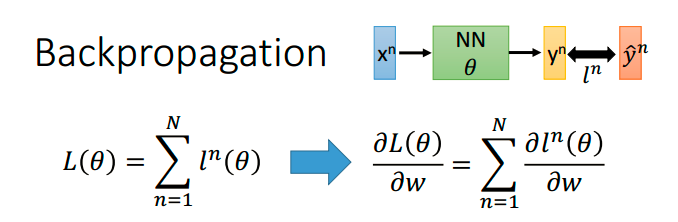
因为神经网络有很多层,那么我们就必须用chain rule一步一步的计算。$L(\theta )$是$l^n$的summation,所以我们只关注单个$l^i$就可以了。
先尝试从前往后计算,考虑二维的简单网络,我们求偏导数$\frac{\partial l}{\partial w}$:
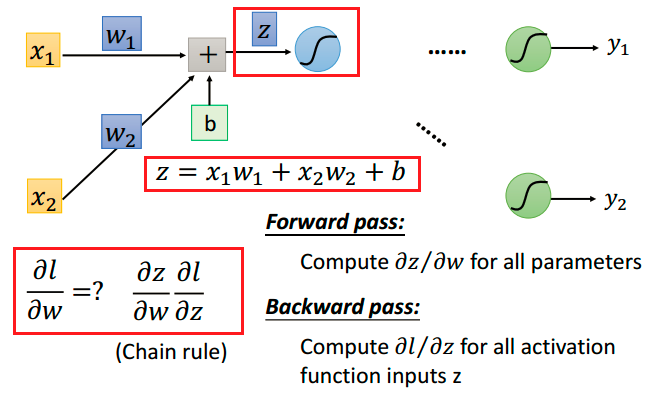
$\frac{\partial z}{\partial w}$ 很明显,就是对应的输入值,那么我们只需要将不同层neurons的输出值计算出来就可以了。
重点在第二部分$\frac{\partial l}{\partial z}$ ,我们再用一次chain rule:
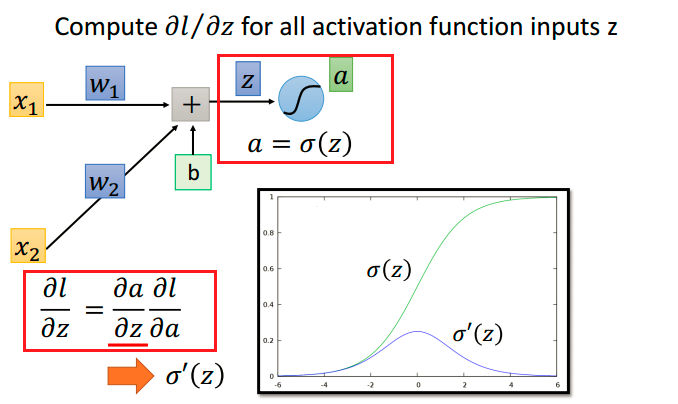
$\frac{\partial a}{\partial z} = {\sigma}’ (z)$,这个也好计算。接下来我们就要计算$\frac{\partial l}{\partial a}$。这里记住$l$是神经网络最后计算结果$y$的函数,还是需要用chain rule计算偏导数:
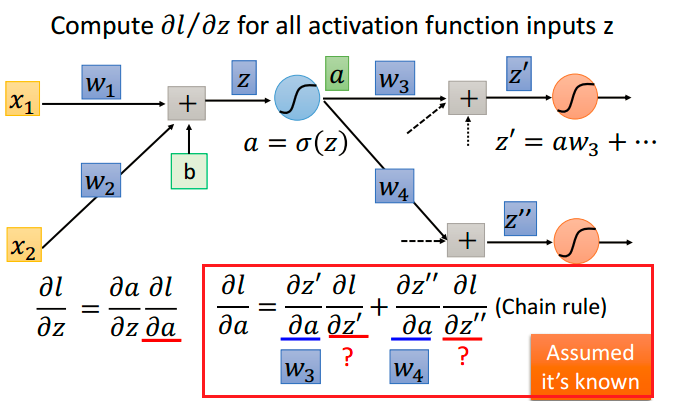
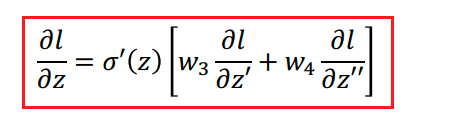
$\frac{\partial l}{\partial z}$ 是下一层 $\frac{\partial l}{\partial z}$的加权summation。我们就需要这样递归的一步一步计算下去,直到输出层,才能得到该层的 $\frac{\partial l}{\partial z}$。
- 最后一层的 $\frac{\partial l}{\partial z} = \frac{\partial l}{\partial y} \frac{\partial y}{\partial z}$,这两项都是可以直接计算出来的,递归终止。
$\frac{\partial l}{\partial z}$依赖于后层的 $\frac{\partial l}{\partial z}$。显然我们应该从最后一层反过来计算 $\frac{\partial l}{\partial z}$,因为从后往前计算所有的 $\frac{\partial l}{\partial z}$简单直观多了,这就是backpropagation。
总结一下,用gradient descent优化神经网络,重点是如何计算梯度$\frac{\partial l}{\partial w}$。使用train rule分解为两部分$\frac{\partial z}{\partial w} \times \frac{\partial l}{\partial z}$ :前半部分也就是前一层的神经元输出(第一层就是输入值)在forward pass 阶段计算;后一部分从最后一层开始,逐层往前计算$\frac{\partial l}{\partial z}$:
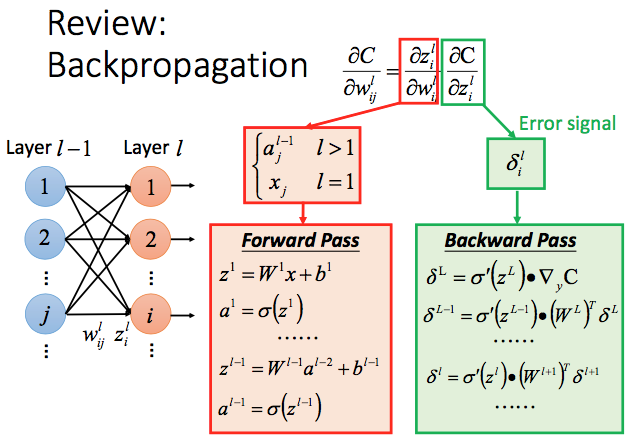
具体的计算流程如下图,上标表示层,下标单数字表示该层排列号,双数字,如$w^l_{ij}$, $i$表示l层中的排列号,$j$表示前一层$l -1$层的排列号 :
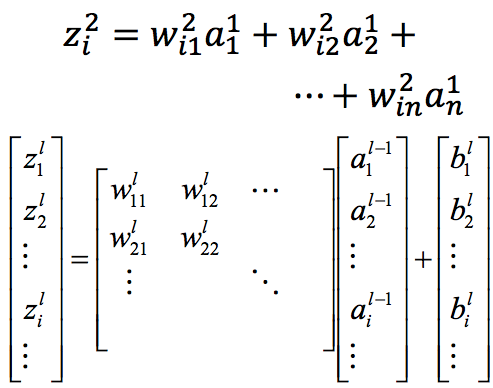
稍复杂的地方是bp中的这个迭代过程:$\frac{\partial C}{\partial z^l} = \frac{\partial a^l}{\partial z^l} \frac{\partial C}{\partial a^l} = {\sigma}’ (z^l)\frac{\partial C}{\partial a^l} = {\sigma}’ (z^l) \frac{\partial z^{l + 1}}{\partial a^l}\frac{\partial C}{\partial z^{l + 1}} = {\sigma}’ (z^l) \left({W^{l + 1}} \right) ^\mathrm{\top} \frac{\partial C}{\partial z^{l + 1}} $. 最后这个组合$\left( {W^{l + 1}} \right) ^\mathrm{\top} \frac{\partial C}{\partial z^{l + 1}}$实际上就是前面讲到的下一层权重与偏导数的summation,只不过这地方用矩阵乘法的方式计算。转置是因为我们定义的$W$下一层作为横轴,所有要转一下。最后得到的$\frac{\partial C}{\partial z^l}$是一个vector。
BP的计算图解释
还可以用计算图的方法解释BP的过程。计算图computational Graph是一种描述function的形式,node代表变量(scalar,vector,tensor…), edge代表操作,如函数$e = (a+b) \times (b + 1)$用计算图表示:
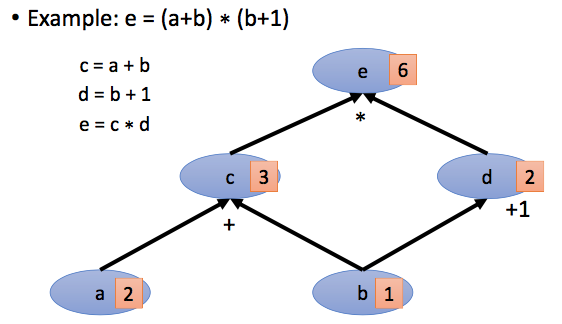
全联接网络的计算图表示
我们以一个两层神经网络为例:
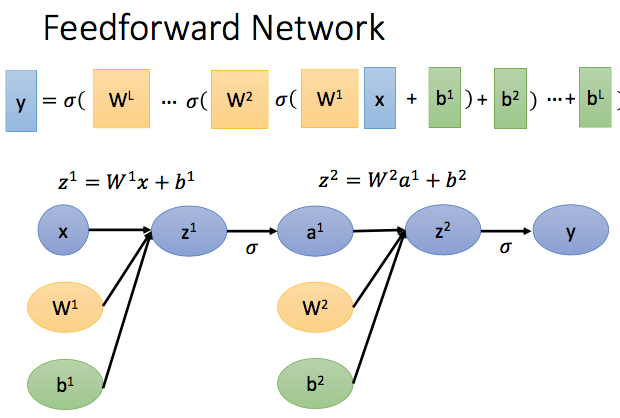
梯度的BP计算过程我们使用计算图来完成:
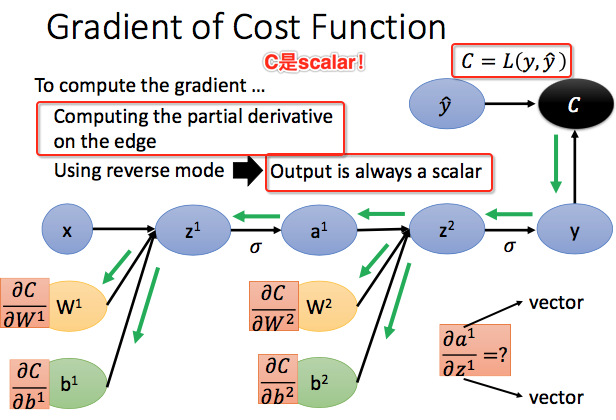
我们需要从最后一层开始逐层往前计算偏导数。vector$\boldsymbol{y}$对vector$\boldsymbol{x}$的偏导数是一个Jacobian Matrix,高度是y的维度,宽度是x的维度。
下面还是以MNIST计算为例。
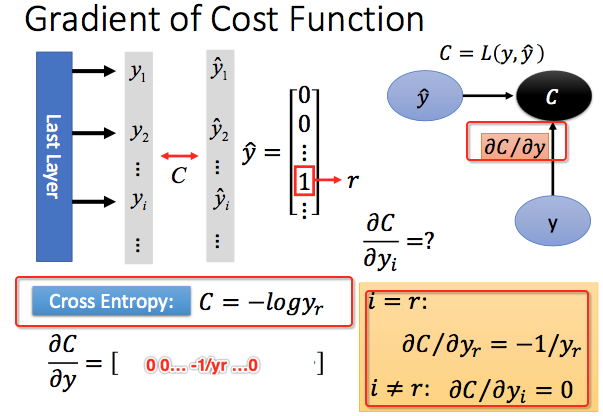
- 求$\frac{\partial C }{\partial y}$, $C$采用corss entropy,即$C = -log y_r$。由于$C$是一个scalar,所以结果是大小为 $1 \times len(y)$的matrix。$r$是真实值$\hat{y}$中1的位置,该位置$\frac{\partial C }{\partial y_{r = i} }= 0$,其他$\frac{\partial C }{\partial y_i }= 0$:
- 接着求$\frac{\partial y }{\partial z^2}$。这里激活函数使用sigmod。$\frac{\partial y }{\partial z^2}$结果是一个Jacobian Matrix,由于y就是该层neurons的输出,每个y对应一个neuron,即$y_i = \sigma (z^2_i)$。那么这个matrix只用$i = j$ 处才值,其他地方偏导为0,既是一个diagonal matrix:
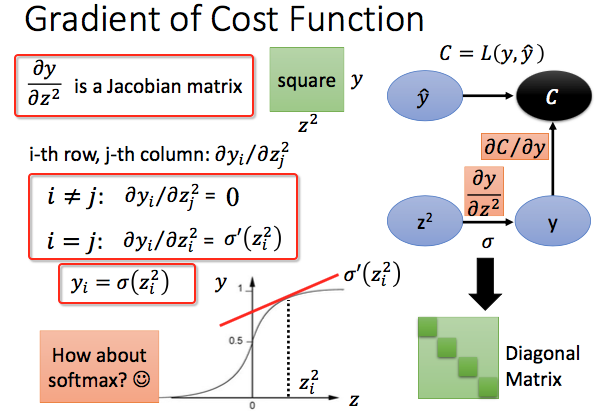
注意若激活函数是softmax,就不是diagonal matrix了,因为每个z都对y由贡献。
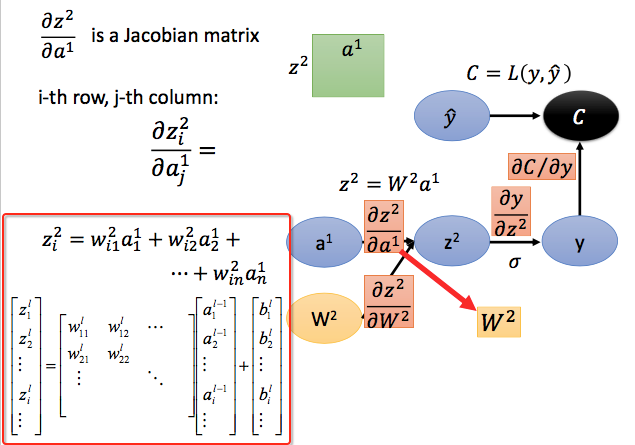
- 接下来就是求$\frac{\partial z^2 }{\partial a^1}$,同样也是一个Jacobian matrix,偏导就是对应的权重值,整个matrix就是$W^2$:
- 求$\frac{\partial z^2 }{\partial W^2}$,$W^2$是一个matrix,结构如下:

$z^l_i$只与计算该值的$w^{l}_{ij}$相关,如下图,所以最后的结果是一个类diagonal mtrix,值为$a^{l -1}$ :
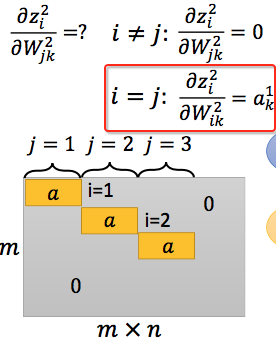
最后我们要求$\frac{\partial C }{\partial W^1}$,就是将路径上的所有偏导乘起来就可以了,注意最后结果的维度, 高度为1,宽度为$m \times n$:
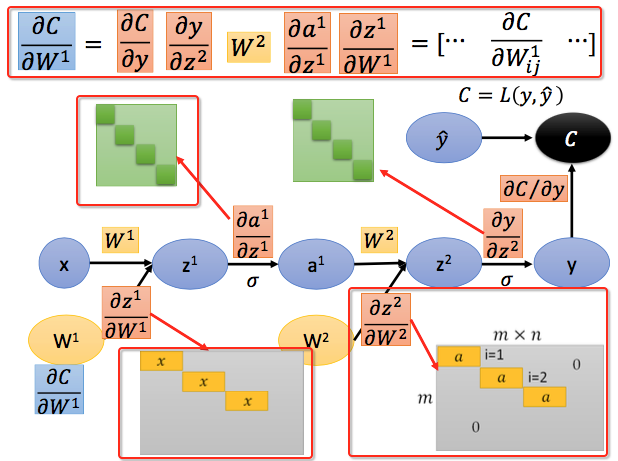
计算图的结果和采用BP是一致的。计算图貌似只使用Backforward过程,但$a$的计算都需要forward progress处理。

