前面我们将PGM经过转换,得到一种新的分类方法逻辑回归:
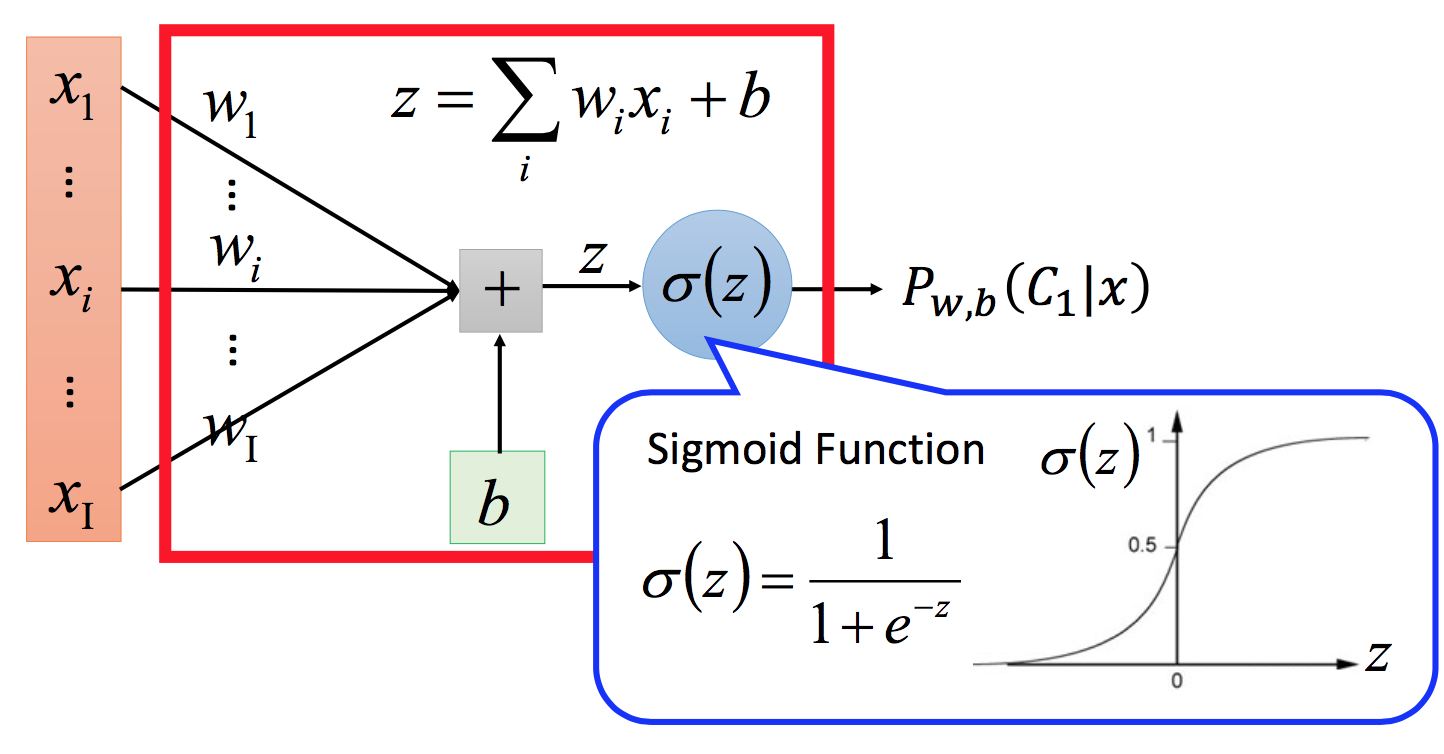
对应的Function set:
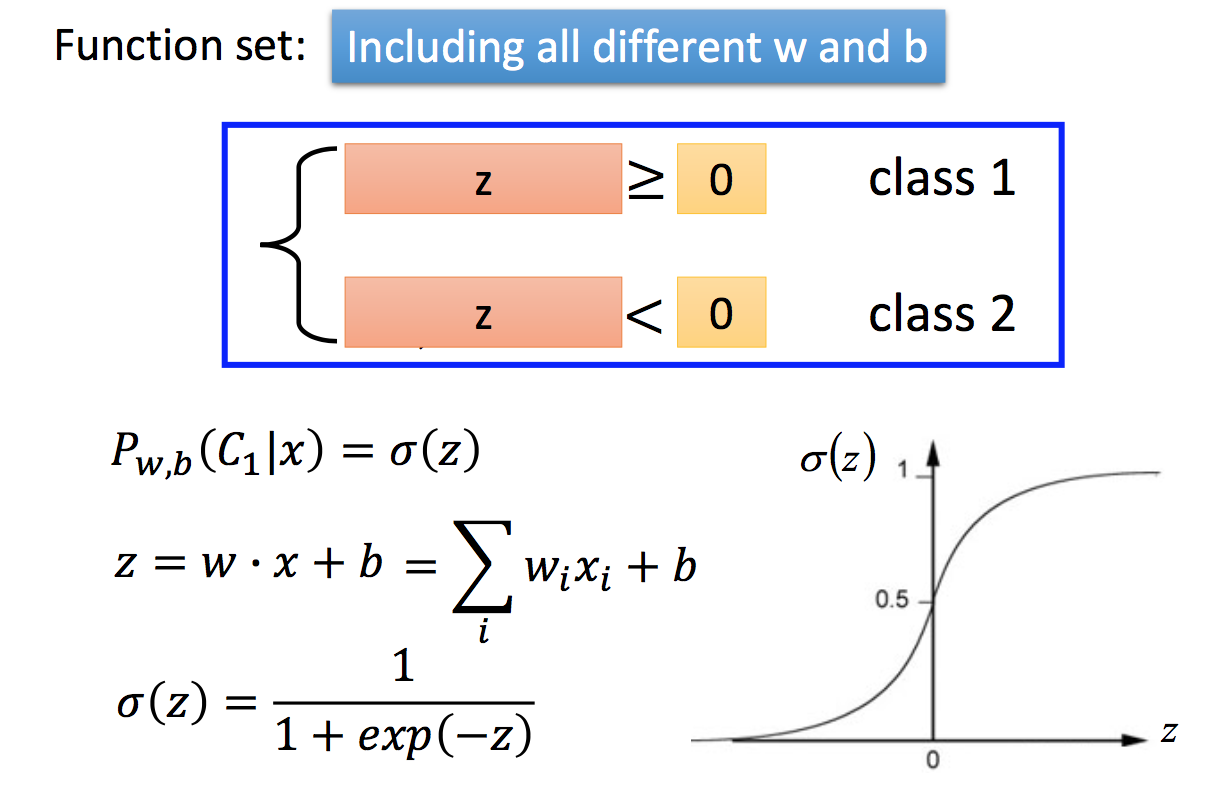
下面就是要获取最合适的$w,b$,还是使用最大似然估计:

上面$(1-f_{w,b}(x^3))$表示$c2$类的概率。 我们在最大化似然估计前面加上负号,这样就转为了一个最优化问题。因为函数全是乘法,且sigmoid中有指数,我们开$ln$,整个函数表示成加法就简单了:

问题就变为:$ argmin \sum -[\hat{y}lnf(x^i) + (1 - \hat{y}^i)ln(1 - f_{w,b}(x^n))]$ 。
该公式另一种解释是两个Bernoulli分布的交叉熵:

交叉熵越小,说明分布越接近,也就是我们想得到的目标函数更接近训练集的分布。
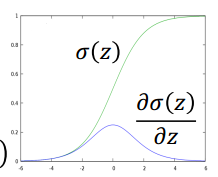
然后我们就是要优化这个公式,还是梯度下降:求出梯度,然后用学习率更新。$f$是一个sigmoid函数,有$\sigma (z)’ = \sigma (z)(1 - \sigma (z))$ , 这个导数很容易推出,我们看一下sigmoid函数图,就能发现,导数数在0点值最大,两边小:
梯度计算过程如下:
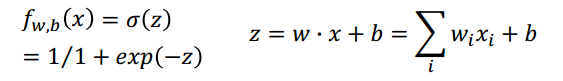


最后我们得到更新公式,和线性回归形式一样,但这里的y只能取1或者0。可以发现,与$\hat{y}$差别越大,step也就越大。
非线性边界
对于下面的分类边界:
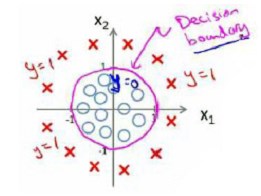
需要用曲线才能分隔 $y=0$的区域和$y=1$的区域,我们使用二次方程:
$$f_{w,b}(\boldsymbol{x}) = \sigma (b + w_1 x_1 + w_2 x_2 +w_3 x_1^2 +w_4 x_2^2)$$
- 假设参数是[-1 0 0 1 1],则判定边界恰好是圆点在原点且半径为1的圆形。
- 还可以用更复杂的模型来适应非常复杂形状的判定边界:
$$f_{w,b}(\boldsymbol{x}) = \sigma (b + w_1 x_1 + w_2 x_2 +w_3 x_1^2 +w_4 x_1^2x_2 + w_5 x_1^2x_2^2 + w_6x_1^3x_2 + …)$$ - 如何选择这些模型??:观察数据
Why not Square Error
前面我们的评价函数是通过最大似然估计得到的,为什么不用线性回归中的square error呢?我们可以计算一下,得到square error的梯度:

发现,在当$\hat{y} ^ n= 1$时,$f = 1 OR 0$ 都会使得梯度等于0;$\hat{y} ^ n= 0$时也会出现这种情况。这样square error会很平坦,很难收敛。
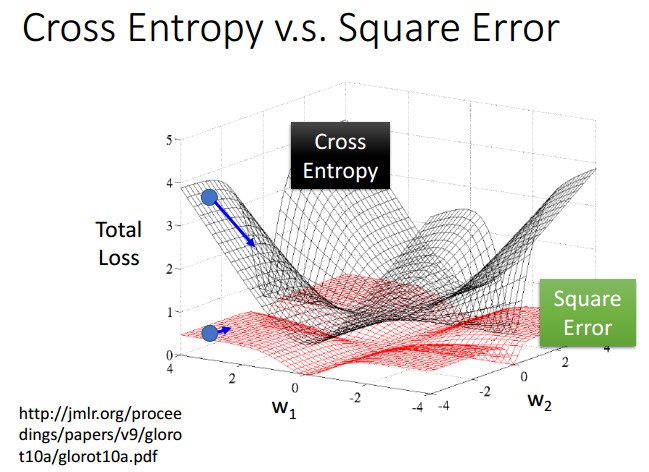
对比一下根据最大似然得到的交叉熵和square error两种cost function图,前者陡峭容易收敛,后面平坦,很难甚至无法收敛:
最后我们看一下线性回归和逻辑回归的对比:

LR vs PGM
逻辑回归和概率生成模型虽然都是来自同一个模型(function set相同),但是最终会选择不同的目标函数。

- LR最后的w,b更多的是和训练集结合。
- PGM包含统计信息更强烈,概率分布带来的额外”脑补“会使得这个模型可能做出一些不正确的判断;
- 一般认为LR准确率更高。
- PGM更适合小训练集的情况,另外对noise容忍度高
多类与softmax
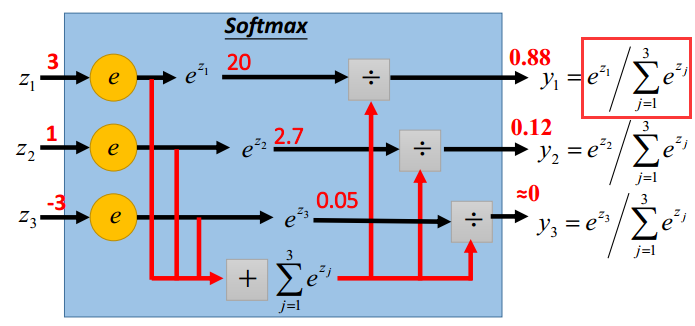
多类的分类我们可以采用softmax分类,以三个类分类为例。我们为每个类使用$w,b$,得到每个分类的概率,有:

最后得到的不同z,用softmax归一化:先取指数,然后归一化得到概率:
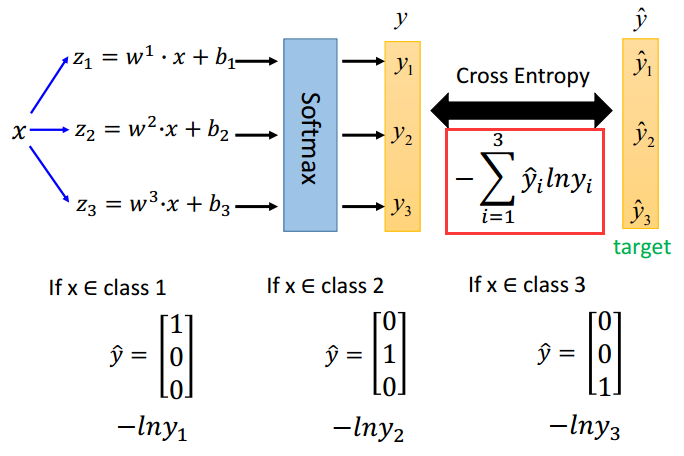
训练方法类似二分类,最后得到一个3分布的交叉熵:
Limitation of Logistic Regression
像逻辑回归这类的线性模型没法区分出异或操作:
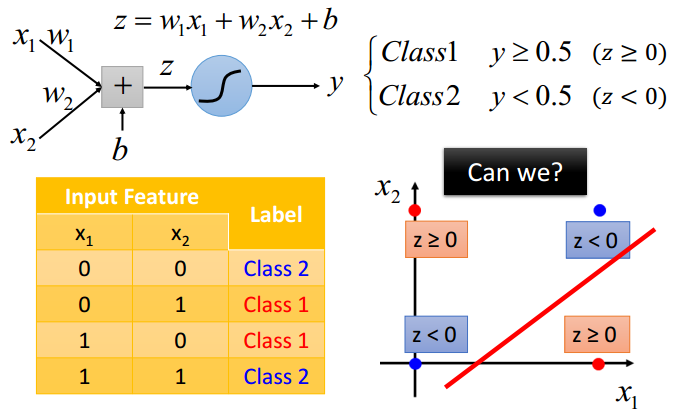
但是我们对$\boldsymbol{x}$做一个转换后,就能分了:
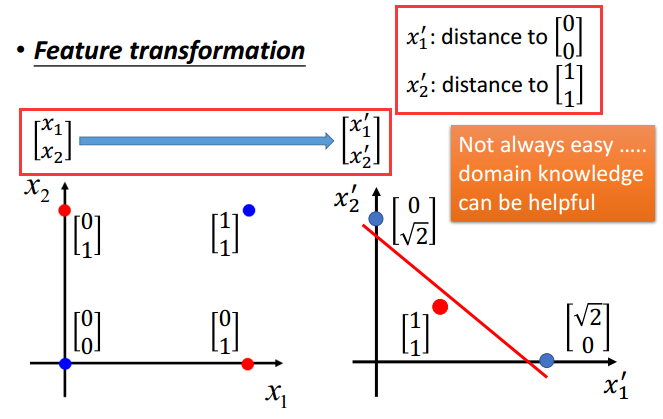
但是除非你有邻域知识能后帮助你找到这个转换,如异或例子。大多数非线性场景我们无法直接获得这种转换。
怎么办? 我们可以用LR交叠的方式先获取一个转换,然后在执行分类:
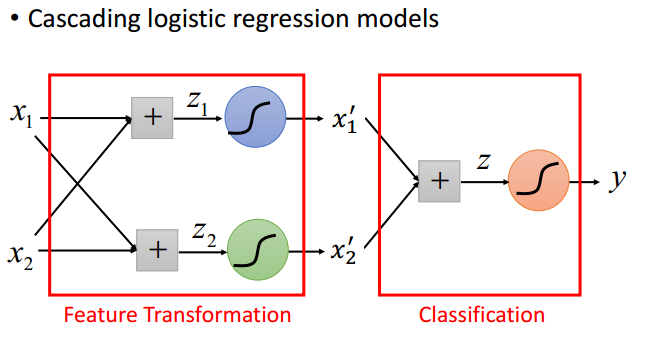
这就是神经网络了!

