正则化的目的就是把曲线拉得缓和些。
过拟合high variance
我们可能有很多的特征,训练出来的模型和训练集拟合的也非常好,但对新数据的预测却不准,这有可以就是过拟合.
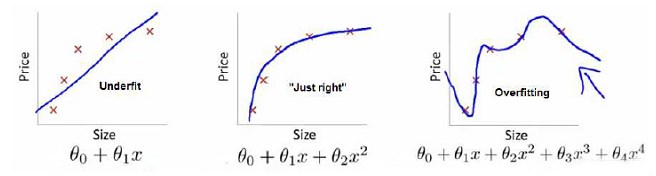
- 上面分别是: 线性/欠拟合;二次/恰当;4次/过拟合
- 但不是说用的4次就没有二次好,而是次数越多,θ 值会变得非常大以达到能拟合训练集的目的,曲线的震荡幅度也会非常大。
- 我们需要曲线平滑些,需要一些regulated校准。
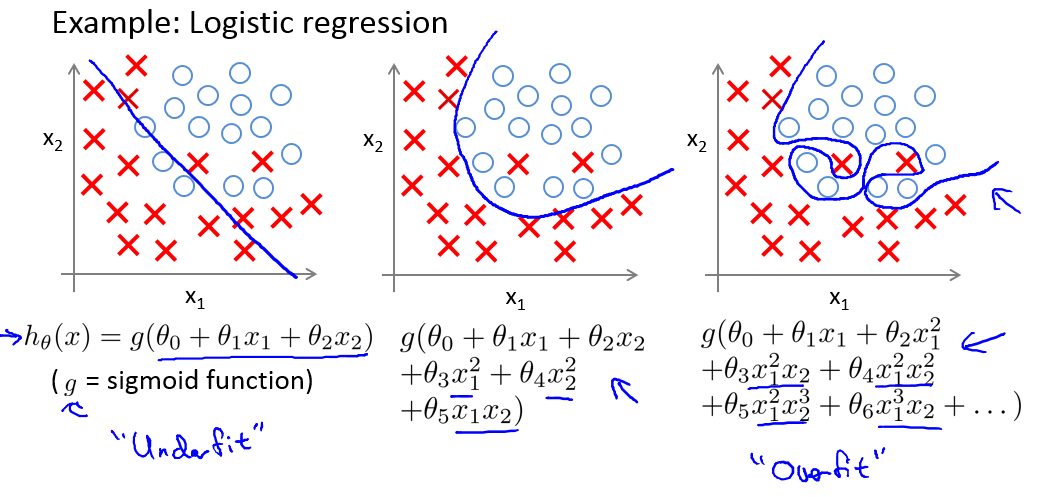
### Logistic Rgression逻辑回归中的过拟合
- 左图欠拟合:high bias: low polynomial
- 中间quadratic fit
- 右图 high polynomial 过拟合: high variance
如何应对过拟合?
- 1 减少feature的数量:去除贡献少的features
- 可以手工选择,也可以使用Model selection algorithms,如PCA
- 2正则化regularization (有时也称penalty惩罚)
- 保留所有的特征,但是减少参数的取值范围(magnitude):减少该参数对预测的贡献
- 更小的θ值减少了overfiting的可能
- 当有很多的features且都对最终结果有较多贡献时,这是个很好的减少过拟合的办法。

正则化代价函数(REGULARIZATION COST FUNCTION)
以上面4次方回归为例:
$$h_{\theta}(\boldsymbol{x}) = \theta_0 + \theta_1 x_1 + \theta_2 x_2^2 + \theta_3 x_3^3 +\theta_4 x_4^4$$
- 要大大减少$\theta_3$和$\theta_4$的大小,我们要做的便是修改代价函数,在其中$\theta_3$和$\theta_4$设置一点惩罚。修改后的代价函数如下:
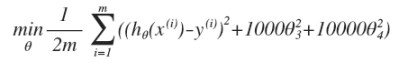
- 这样$\theta_3$和$\theta_4$ 的值会很小 (约等于零),3次方和4次方对最后的结果影响也就小了,模型接近 二次方程 了。
- 对于非常多的特征,并不知道其中哪些特征我们要惩罚,那么就对所有的特征进行惩罚,得到了一个较为简单的能防止过拟合问题的假设:
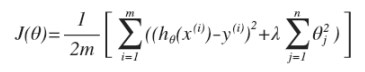
- $\lambda$ 正则化参数(Regularization Parameter)
- 注意:根据惯例,我们不对θ0进行惩罚。
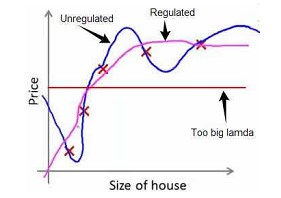
- $\lambda$ 越大,惩罚越重
- $\lambda$太大也不行,就欠拟合了:
- $\lambda=10^10$ ,除了$\theta_0$,其他的$\theta$都接近零了,这样hypothesis 就成了找最合适的一个水平线:$h_{\theta}(x) = \theta_0$:显然,欠拟合了。

- $\lambda$ 有自动选择的算法,后面会讲。
正则化线性回归(REGULARIZED LINEAR REGRESSION)
正则化线性回归的代价函数为:
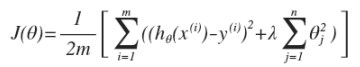
- 因为没有对$\theta_0$正则化,所以分开处理:
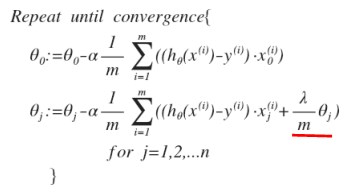
- 对于$j=1,2,…,n$ 时的更新式子 重写一下,看得更明白:
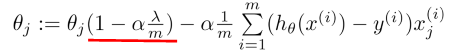
变化在于,每次都在原有算法更新规则的基础上令$\theta_j$值减少了一个额外的值($\theta_j$的系数是一个常数,所以每次都要减小一点):造成$\theta_j$变的更小,影响也就更小了。
也可以利用正规方程来求解正则化线性回归模型,方法如下所示
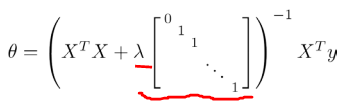
上式中的矩阵尺寸为$(n+1)\times (n+1)$。
正则化逻辑回归(REGULARIZED LOGISTIC REGRESSION)
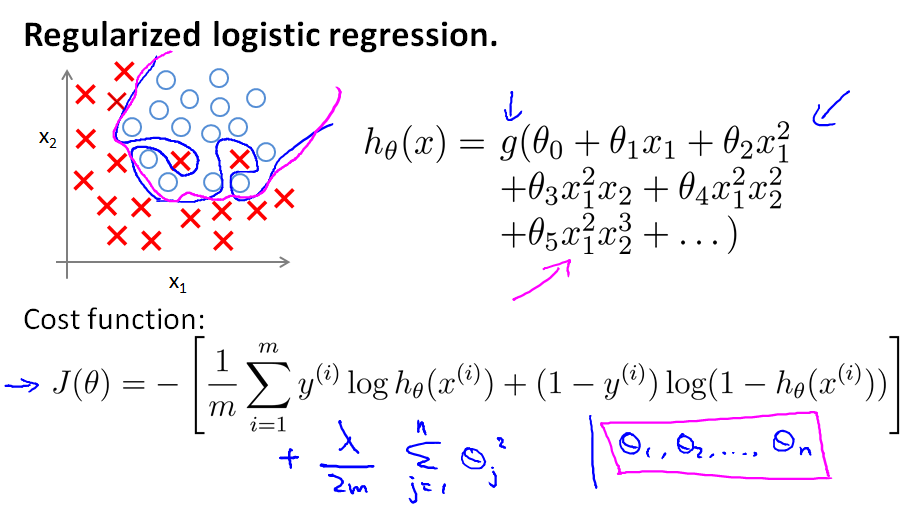
- 对于逻辑回归,我们也给代价函数增加一个正则化的表达式,得到:
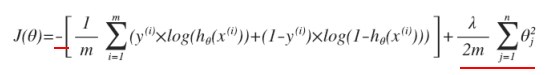
类似,最小化该代价函数,求导,注意区分$\theta_0$:
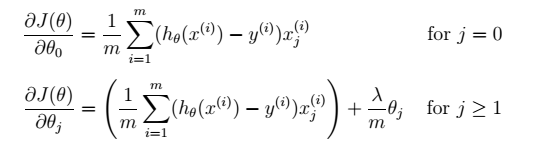
得出梯度下降算法为:
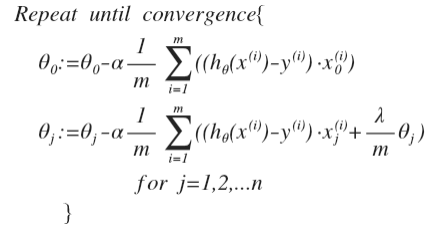
看上去同线性回正则样,但是知道$h_{\theta}(x) = \sigma (\theta ^{\mathrm{\top}}\boldsymbol{X})$,所以与线性回归不同。

