在介绍洛基回归模型之前,我们先了解以下概率生成模型。
贝叶斯模型给了我们发现反向概率的方法:

对于一般的分类模型,我们也可以采用类似的方法,若果$P(C_1 | \boldsymbol{x}) > 0.5$ , $ \boldsymbol{x}$属于$C_1$,否则属于$C_2$。
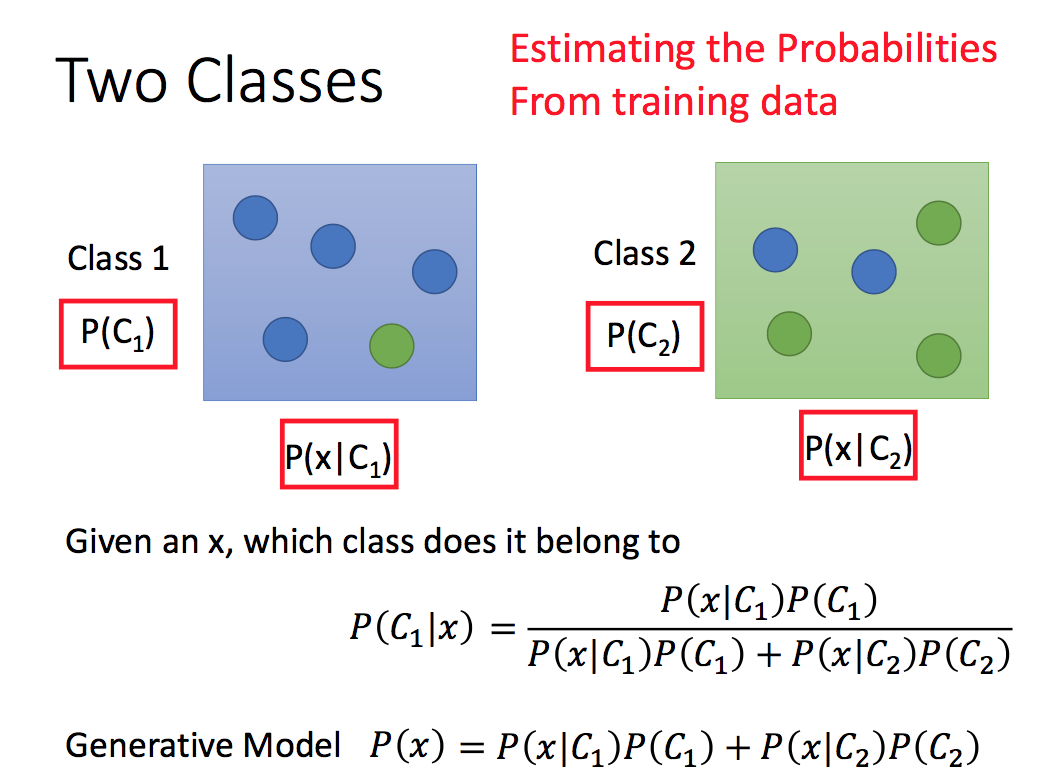
上面的box,所有的概率分布都很清楚,可以直接得到最终的概率。但对于一个分类来说,我们要求$P(x|C_i)$就需要知道不同分类的概率分布。以一个Pockmon游戏中宠物分类的例子,取了两个类别水类(79个)和普通类(61个)的宠物,每个宠物有6个features。 对于训练集来说,$p(c_1), p(c_2)$是常数,统计一下就可以:

对于一般的分类模型,我们用features向量$\boldsymbol{x}$来表示一个物种。剩下的就是要求$P(\boldsymbol{x}|C_i)$:也就每一个分类中,一个未知$\boldsymbol{x}$在该类出现的概率/密度函数。我们目标是就是需要根据sample数据,得到不同分类的概率密度函数$P(\boldsymbol{x}|C_i)$。假设每个分类服从高斯分布:
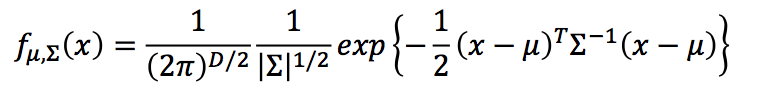
我们就需要根据sample 数据得到均值$\mu$, 协方差矩阵covariance matrix $\Sigma$。很自然想到使用最大似然估计得到$\mu ^, \Sigma ^$:得到最接近sample数据的高斯分布。
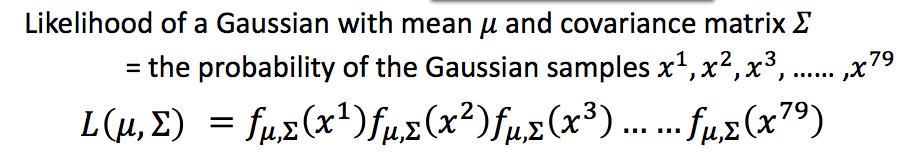

我们根据最大似然估计,对水类和普通类得到对应的高斯分布(以两个features为例):
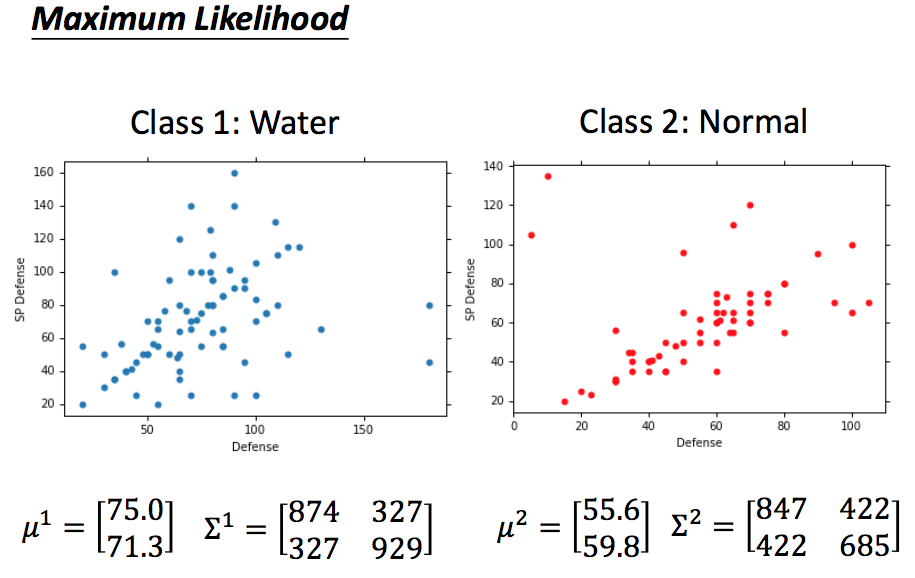
对于一个未知的物种$\boldsymbol{x}$,我们就可以得到他在不同类别中的概率,可以用前面的贝叶斯做分类了:

最后在测试集的结果不太好,准确率只有47%,用上全部6个features的话,准确率是64%。
### 模型改进
前面两个分类的covariance matrix 是在各自分类中计算得到的,结果不同。现在把他们的covariance matrix 变成一个,目的是减少模型的偏差variance,也就是降低模型复杂度,减少overfitting。计算方法也很简单,就是将原来分类的$\Sigma ^i$做一个加权平均即可。
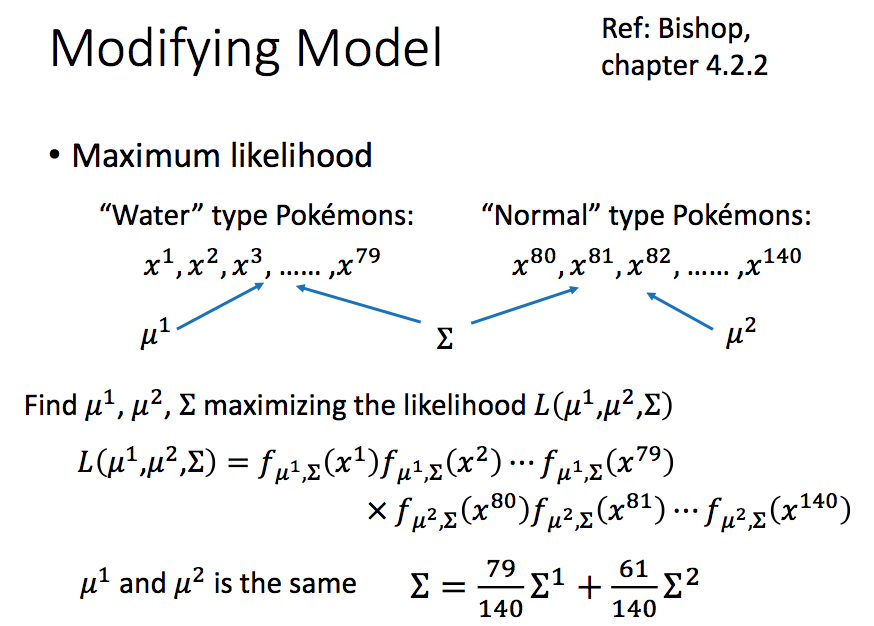
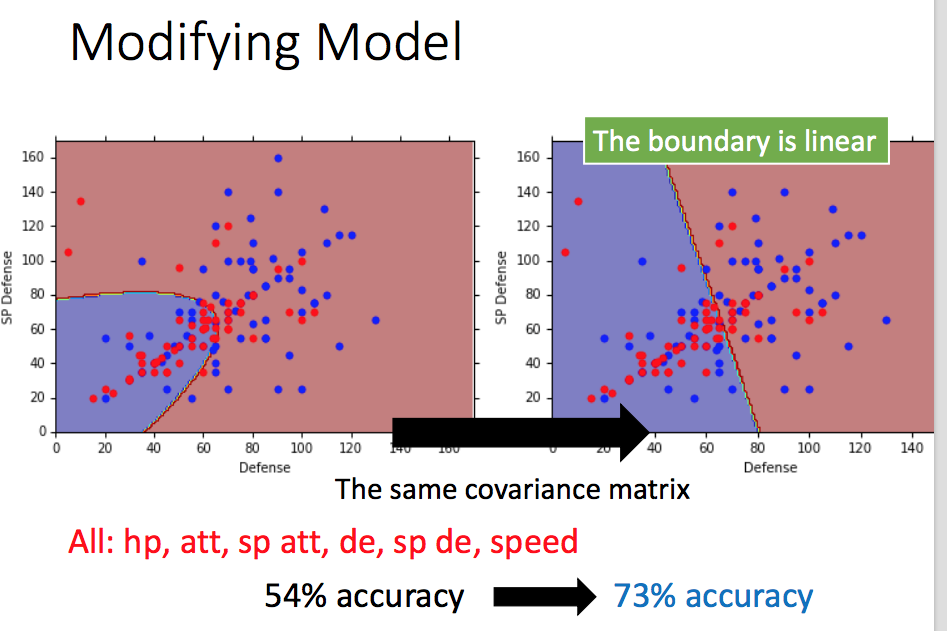
再用新的参数来做分类,准确率提高到了73%!。可以看出,分类边界变成了线性边界,分类的模型也就变成了线性模型了,后面我们再看为什么变成了线性模型。
总结一下,这种模型分为3步:

概率分布的选择
前面我们使用的是多维高斯分布,当然你也可以使用其他的概率分布做,如下面用一维的高斯分布,假设所有的featutes之间独立,那么这就是朴素贝叶斯分类了:

后验概率和Sigmoid函数
我们将上面的贝叶斯公式做一下转变:
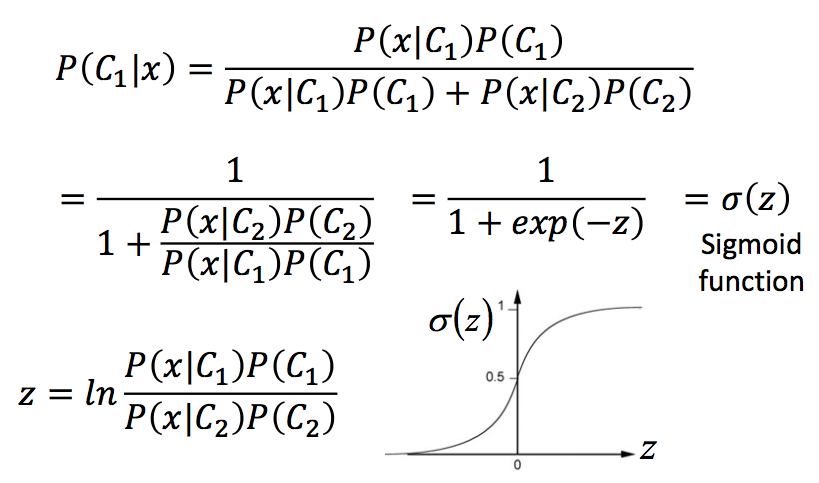
我们看到,我们将后验概率表示成一个sigmoid函数,而$z$是$\boldsymbol{x}$在两个分类中概率比率的ln值,将出现概率的对比映射到(0,1) 之间,很明显:
- 当$\boldsymbol{x}$在两类出现的概率相同时,$z = 0$,就是sigmoid函数中间的点。
- 当$\boldsymbol{x}$在类1中概率更大时,$z > 0$就是右侧。
- 当$\boldsymbol{x}$在类1中概率更小时,$z < 0$就是左侧。
这样我们用sigmoid表示后验概率:

计算$z$的表达式:


$z$看着挺复杂的,那么把上面的$\Sigma ^1, \Sigma ^2$按照前面的做法合一做进一步简化,可以更清晰的将$z$表示为一个一维函数了:

(哇哇!!逻辑回归的味道来了!)这样经过一系列计算,我们将PGM模型转换为了基于sigmoid的线性模型(当然我们是简化合并了$\Sigma$),这就能解释上面的宠物分类在$\Sigma$合并后由曲线的分类边界变成了线性的分类边界了。

