单变量线性回归 linear regression with one variable
房价预测:
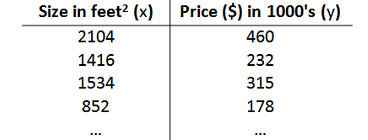
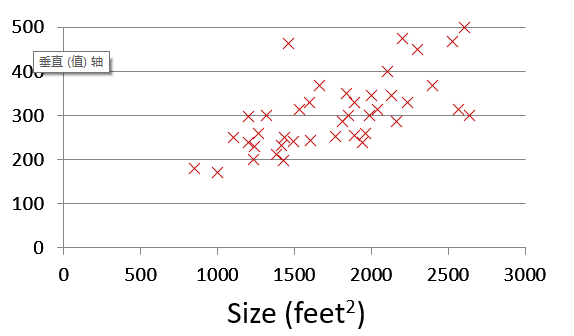
问题描述:
- $m $ 代表训练集中实例的数量
- $x $ 代表特征/输入变量
- $y $ 代表目标变量/输出变量
- $(\boldsymbol{x,y}) $ 代表训练集中的实例
- $ (x^{(i)},y^{(i)}) $ 代表第i个观察实例
- $h $ 代表学习算法的解决方案或函数也称为假设(hypothesis):
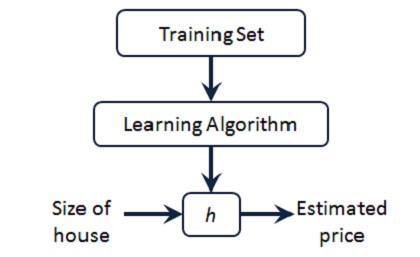
- 由训练集通过学习算法,学习得到一个假设$h$(这个假设就是一个模型),新的数据通过h,预测出房价。
如何表达$h$?这个例子中,我们先用一个线性方程:
$$h_{\theta}=\theta_0 + \theta_1 x$$因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题.
- 线性关系(Linearity)是变量与自变量成一次方的函数关系。其画在函数图上会呈现一条直线。
代价函数cost function
- 确定了$h$的形式,我们就要为模型选择合适的参数parameters : $\theta_0, \theta_1$。
- 预测值与实际值的差距就是建模误差modeling error
- 我们选择的建模误差的平方和( square error function)作为模型的代价函数,目标就是选择使得代价函数最小的模型参数。
总结
- Hypothesis: $h_{\theta}=\theta_0 + \theta_1 x$
- Parameters: $\theta_0, \theta_1$
- Cost function: 其中$m$为样本个数
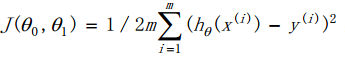
- Goal : 最小化代价函数
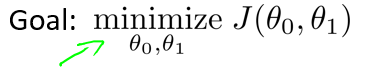
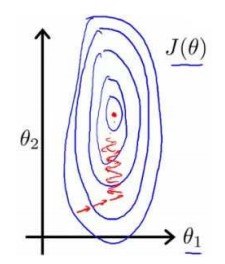
- 下面的等高图,三个坐标分别为 $\theta_0, \theta_1, J(\theta_0, \theta_1)$:我们就是要找到那个凹点,使得$ J(\theta_0, \theta_1)$值最小。
- 如何找?下面介绍一种方法来求解代价函数的最小值。
梯度下降Gradient descent
- 思想:初始化参数(随机找一个参数组合 $\theta_0, \theta_1, … \theta_n$, 目标是寻找下一个能让代价函数值下降最多的参数组合,持续这么做直到一个局部最小值(local minimum)。
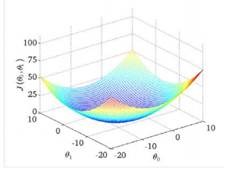
- 因为没有试过所有的参数组合,所以不能确认局部最小值是否是全局最小值(global minimum)
- 选择不同的初始参数组合,可能会找到不同的局部最小值。下图显示使用不同的初始值到达的不同的local minimum:
Gradient descent algorithm
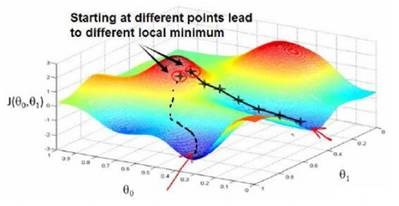
- 沿下降最快的方向(导数)梯度下降(参数必须同步更新),下降率由learning Rate控制:
- 下降速度最快的方向为什么是导数方向:直观的例子,在一个下坡路,找一条离坡地最近的路:当然是沿着坡道直下(导数方向)而不是走Z字行下:上坡为省力选择Z字小坡度上,但是距离也更长;上图也可以想象为一个山脉,你想找到一条离山谷最近的路,当然是走最陡峭的路最近(这是一种贪婪算法,不一定是最优),最陡峭也就是导数方向(曲面的导数)。

为什么是减去?下图分为了左右两部分下降:左边部分因为导数是负数,减的话就成加了:
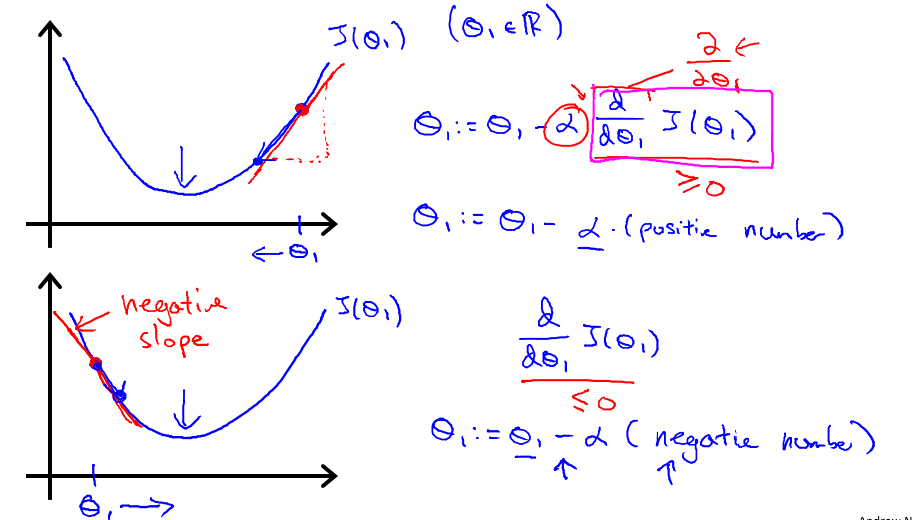
- 这样每个参数都是在它的导数即下降最快的方向下降。
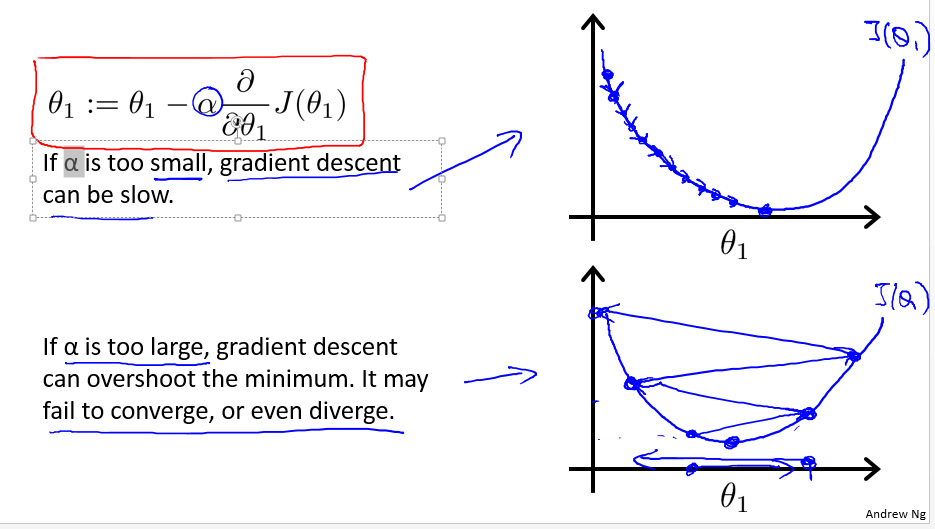
学习率 α
- 太小,学习太慢
- 太大,可能错过最优点:fail to converge or even diverge
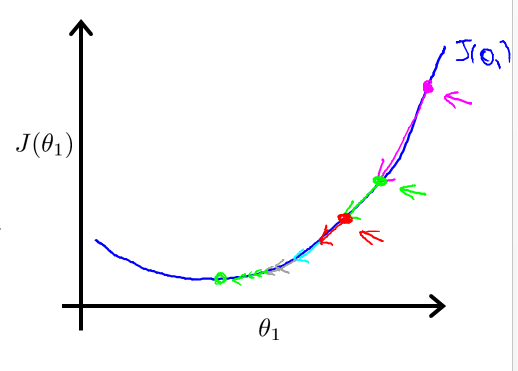
- 即使固定α,因为随着导数变小,后面的step也会逐渐变小的,所以也能够converge:
收敛的标准
- 最好当然是变化为0
- $J(\boldsymbol{\theta}) 变化不超过过1/1000,我们就认为converge了
批量梯度下降(batch gradient descent)
- batch: 每次都用到所有的training data
对于前面的线性回归问题,运用batch gradient descent方法,关键是求出代价函数的导数,首先回顾一下模型:

- 计算两个参数的倒数:

- 这样我们将梯度下降公式做一下替换:


References
- 吴恩达,《Machine learning》,Coursera.

