实际应用场景中一般都是多个features特征,例如房间数,楼层等,构成一个多变量的模型,模型中的特征为$(x_1,x_2,…,x_n)$:

- $n$ 特征的数量
- $\boldsymbol{x}^{(i)}$ 第$i$个训练实例,是特征矩阵中的第$i$行,是一个向量(vector)。
- $x^{(i)}_j $ 第$i$个训练实例的第$j$个特征,即特征矩阵中第$i$行的第$j$个特征。
多变量线性回归
- 支持多变量的假设$h$ 为:
$$h_{\theta}(x) = \theta_0 + \theta_1 x_1 \theta_2 x_2 + … + \theta_n x_n$$
- 有 $n+1$ 个参数和$ n$ 个变量,为了方便处理,引入$x_0 = 1$,公式转换为:
$$h_{\theta}(x) = \theta_0 x_0 + \theta_1 x_1 \theta_2 x_2 + … + \theta_n x_n$$
这样,参数 $n+1$ 维的向量,训练实例也是一个$n+1$ 维向量,我们就可以直接用矩阵操作了。
- 特征矩阵(训练实例) 维度是 $m×(n+1)$, 公式也就简化为:
$$h_{\theta} (\boldsymbol{X}) = \theta ^\mathrm{\top} \boldsymbol{X}$$
多变量梯度下降gradient Descent for multiple variables
与单变量梯度下降相似,构造损失函数:
$$J(\theta_0 , \theta_1 ,…,\theta_n) = \frac{1}{2m} \sum^m_{i=1}(h_{\theta} (x^{(i)}) - y^{(i)})^2$$
对$\theta_i$的参数求导,批量梯度下降,直到收敛:
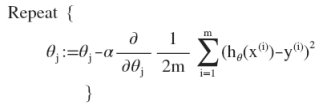
求导后,代入:

计算过程是先随机选取一系列参数值,然后计算预测结果,代入上式,更新参数值,直到参数收敛。
这里会遇到一些问题,一个是不同参数的尺度问题,还有的学习率问题,下面的2个tricks可以帮助解决这些问题:
特征缩放 Feature Scaling
以上面的房价预测为例,房间数为0-5,尺寸是0-2000平方英尺,这样画出来的等高线是一个很长的椭圆,需要很多次迭代才能收敛:
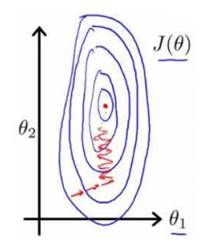
为了使收敛速度更快(另外不同的数据级在其他的算法中可能需要一起操作,大级别的参数会覆盖小级别参数的变化),我们要保证这些特征具有相似的尺度similar scale,可以帮助梯度更快的收敛: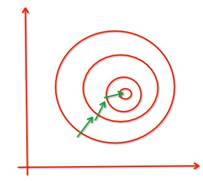
解决的方法是尝试将参数的范围放大[-1, 1]间,最简单的方法是:
$$x_n=\frac{x_n - \mu_n}{S_n}$$
其中 $\mu_n$ 是平均值,$S_n$是 标准差。 简单的说就是这个:
$$x^*_i=\frac{x_i - \bar{x}}{x_{max} - x_{min}}$$
特征缩放也称为: Normalization 归一化
学习率learning rate
- 收敛所需要的迭代次数根据模型不同而不同,可以用迭代次数与代价函数的图标来感官的查看:
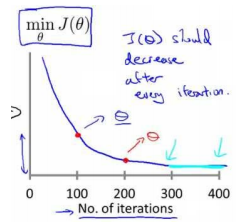
- 代价函数应该在每次迭代后都应该有所减少,直到收敛,上图最后的浅蓝部分就收敛的不错了。
- 学习率过小,迭代次数太多,学习率太大,可能会错过局部最小值,通常考虑下面的学习率:
- 0.01,0.03,0.1,0.3,1,3, 10

